



ANSI Control Sequences
Photo Credits: Unsplash
Introduction
ANSI control sequences are series of characters embedded within text data that, instead of being printed as text, are interpreted by terminals and terminal emulators as functions or commands.
For example, most *nix terminals will print shell prompts in a different color than shell input and output. This is almost always accomplished with ANSI control sequences (which are a subset of ANSI escape sequences).

However, there are a wide variety of use cases for control sequences beyond text formatting. Nearly every interactive or dynamic terminal-based application requires ANSI control sequences to function.
Text Encodings
Using ANSI control sequences requires a basic understanding of text encodings.
It's fairly common knowledge that computer systems store all data (video games, pictures, ebooks, raw text, etc.) as 1's and 0's, or bits and bytes. In order to input, store, and display this data, software designers had to agree amongst themselves how to store different sorts of data: what combination of 1's and 0's would represent an 'A', a 'B', and so on. An agreed-upon set of rules for translating data into 1's and 0's is called an "encoding."
(There's the additional nuance of code points vs encodings, but more on that later.)
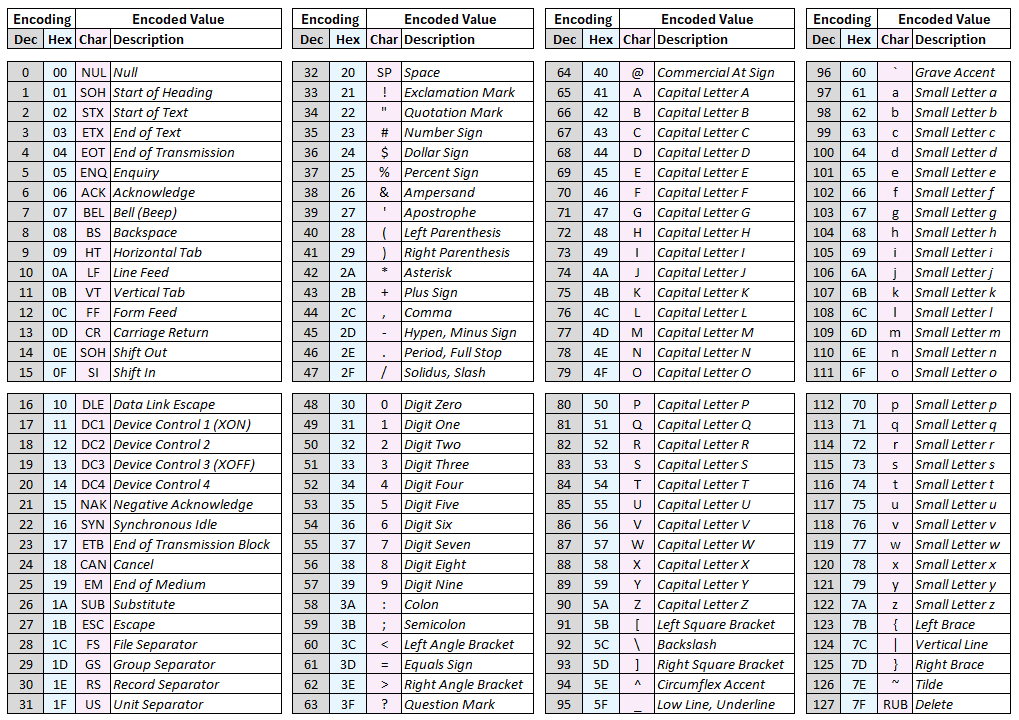
ASCII is the most well-known text encoding. It uses 7 or 8 bits per character and can represent all letters and punctuation marks in the English alphabet.
An "ASCII Table":
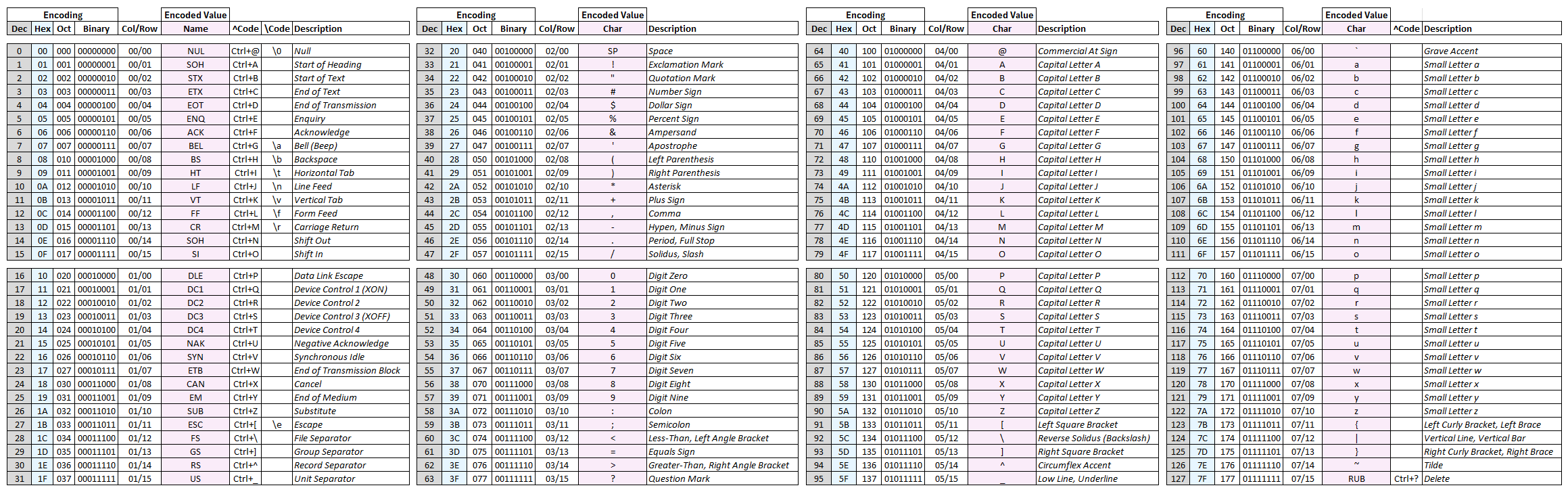
An expanded version of this table is available here
{kind=link}
Non-Printable Characters
While ASCII designates decimal numbers 33 through 126 as regular or 'printable' characters, bytes containing the equivalent of (decimal) 0-31 or 127 are 'non-printable' or 'control' characters.
Most of the ASCII control characters are rarely used today, with some obvious exceptions (line feed, backspace, etc.). For ANSI escape codes, we'll primarily be interested in the escape character (decimal 27).
Code Points vs Encodings
There are two pieces to an encoding:
- Mapping a character to a number, or "code point"
- Defining how code points will be encoded into 1's and 0's
The majority of text-based data today is stored in a Unicode-based encoding. Unicode defines "code points," or assigns a unique number to each character. UTF-8, UTF-16, and UTF-32 all use those code points but differ in their methods for translating those numbers into bits and bytes on disk.
Because Unicode defines so many characters, more than one byte is required to represent many of the numbers assigned to them. To provide efficiency, UTF-8 is a "variable-length" encoding, meaning some characters are represented with a single byte, while others require up to four. UTF-16 uses a minimum of two bytes per character, but also may go up to four, while UTF-32 is a fixed-length encoding that always uses four bytes per character. UTF-32 is less memory-efficient, as much of the data will consist of "leading zeroes."
History of Escape Sequences
The ASCII text encoding was first standardized in 1963 in the ANSI X3.4 standard. ECMA-6 and ISO 646 followed soon after (1965 and 1967, respectively). The version of ASCII defined in ISO 646 is nearly identical to modern ASCII and defined the 'C0' control character set (more on these later).
In the 1970s, video terminals started to become popular. The most well-known examples today were created by the Digital Equipment Corporation (DEC):
- 1970: VT05
- 1975: VT52
- 1978: VT100
- 1983: VT200
Video terminals unlocked many capabilities not possible with teletypewriters/teleprinters. For example:
- Text can be displayed in any number of colors, styles, and formats
- The cursor can easily be moved to any arbitrary location, including next to or over previously written content
- Text previously written to the terminal can be modified or erased
- A program like
vimcan wipe the terminal's display, display its own content, then restore the previous content when complete
Initially, terminal vendors used proprietary or vendor-specific escape sequences to perform these types of operations. ECMA-48 (1976), ANSI X3.64 (1979), and ISO 6429 (1983) standardized most escape sequences, though many terminals continued to support additional escape sequences beyond these. The VT100 was the first terminal to be "ANSI-compliant."
In the 1980s, the xterm program was developed for *nix systems and remains one of the most popular and influential terminal emulators. It was designed to emulate the DEC VT series of terminals and therefore supports both standardized ANSI escape sequences as well as DEC private use functions.
Further reading on xterm
In 2016, Microsoft added support for ANSI escape sequences into its terminals (conhost and Windows Terminal) with the Windows 10 v1511 update. Microsoft based its support for ANSI escape sequences on the xterm program and consequently also supports both standardized ANSI escape sequences and DEC private use functions.
Further reading on Windows Virtual Terminal Sequences
Definitions
The phrase "ANSI escape sequences" is often used synonymously with "ANSI control sequences." Technically, control sequences are a subset of escape sequences. For clarity, here are the definitions from the ECMA-48 standard:
- Control character: A control function the coded representation of which consists of a single bit combination
- Control function: An element of a character set that effects the recording, processing, transmission, or interpretation of data, and that has a coded representation consisting of one or more bit combinations
- Control sequence: A string of bit combinations starting with the control function CONTROL SEQUENCE INTRODUCER (CSI), and used for the coded representation of control functions with or without parameters
- Escape sequence: A string of bit combinations that is used for control purposes in code extension procedures. The first of these bit combinations represents the control function ESCAPE
- Private use: The means of representing a non-standardized control function or mode in a manner compatible with this Standard
Note: See the C1 section under Control Characters for a definition of the Control Sequence Introducer (CSI).
Observations:
- All control characters are (or invoke) control functions, but not all control functions are control characters
- All control sequences are (or invoke) control functions
- All control sequences are escape sequences, but not all escape sequences are control sequences
Control Characters
There are two sets of control characters: C0 and C1. Some standards define methods for switching between standard and non-standard C0 and C1 character sets, but these seem to be rarely used - in modern scenarios, at least. This article will only describe the standard control character sets.
Note: Control characters are sometimes referred to with the shorthand Cc.
C0
The C0 character set comprises the 32 non-printable characters at the start of the ASCII table, and was originally defined in ISO 646, though ISO 6429/ECMA-48 subsequently re-named some codes. These characters are still included in most text encodings (though many are rarely, if ever, used).
C1
The default C1 character set was first defined in ECMA-48/ISO 6429. It defined an additional 32 control characters. They were given both 7-bit and 8-bit encodings. The 8-bit C1 set encodes each control character in a single byte and spans the range of decimal values 128 to 159. To make these control characters available to 7-bit systems (which cannot encode decimal values 128 or above in a single unit), a multi-unit version of each control character was defined by combining the ESC character with the one of the characters between decimal 64 and 95.
(The two-unit versions of the C1 control characters are arguably control functions - since they are defined by the combination of two characters.)
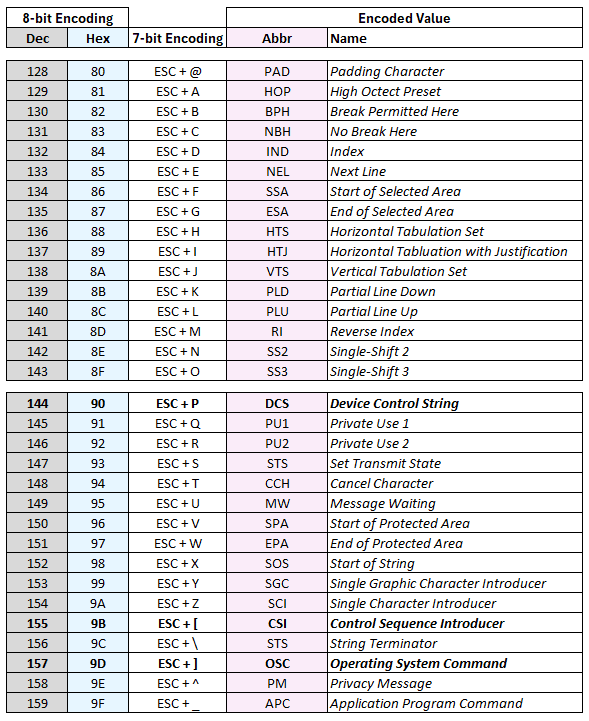
Note that Microsoft has intentionally disabled support for the 8-bit C1 control characters by default (source). Support can be enabled using the DEC private use escape sequence S8C1R (ESC SP 7).
(Documentation on the original DEC S8C1R function is available here)
Control Sequences
Structure
Paraphrasing ECMA-48:
A control sequence has the structure CSI P...P I...I F, where
- CSI is the 7 or 8 bit control sequence introducer (code points
1b 5bor9b) - P...P are Parameter Bytes, which, if present, have code points between
30and3f - I...I are Intermediate Bytes, which, if present, have code points between
20and2f - F is the Final Byte, has a code point between
40and7e, and - together with the Intermediate Bytes, if present - identifies the control function- Final Bytes
70through7eare reserved for private use
- Final Bytes
End paraphrase
In most cases, this looks like:
\x1b[ <zero or more numbers, separated by ";"> <a letter>
As an example, the control sequence \x1b[1;3;4;35m can be read as:
| Characters | Meaning |
|---|---|
\x1b[ | CSI |
1;3;4;35 | Function Arguments |
m | Function |
In this case:
- "m" invokes the "Select Graphics Rendition" function
- "1" sets text to bold
- "3" sets text to italics
- "4" sets text to underlined
- "35" sets the text color to magenta.
Selected ANSI Control Functions
Pn used to denote a parameter
| Acronym | Name | Signature | Description |
|---|---|---|---|
| CUU | Cursor Up | CSI Pn A | Move cursor up by n (default n is 1) |
| CUD | Cursor Down | CSI Pn B | Move cursor down by n (default n is 1) |
| CUF | Cursor Forward | CSI Pn C | Move cursor forward by n (default n is 1) |
| CUB | Cursor Backward | CSI Pn D | Move cursor backward by n (default n is 1) |
| CNL | Cursor Next Line | CSI Pn E | Move cursor to the beginning of the line n lines down (default n is 1) |
| CPL | Cursor Previous Line | CSI Pn F | Move cursor to the beginning of the line n lines up (default n is 1) |
| CUP | Cursor Position | CSI Pn1;Pn2 H | Move cursor to the Pn1th row and Pn2th column |
| ED | Erase in Display | CSI Pn J | Pn=0: current position to end of display; Pn=1, beginning of the display to current position; Pn=2, erase full display |
| EK | Erase in Line | CSI Pn K | Pn=0: current position to end of line; Pn=1, beginning of the line to current position; Pn=2, erase full line |
| SU | Scroll Up | CSI Pn S | Scroll text up by n. New lines fill in from bottom |
| SD | Scroll Down | CSI Pn T | Scroll text down by n. New lines fill in from top |
| ICH | Insert Character | CSI Pn @ | Insert n spaces at current position, shifting existing text to right |
| DCH | Delete Character | CSI Pn P | Delete n characters at current position, shifting space characters in from right edge |
| ECH | Erase Character | CSI Pn X | Overwrite n characters from the current position with a space character |
| IL | Insert Line | CSI Pn L | Insert n lines at the current position |
| DL | Delete Line | CSI Pn M | Delete n lines from the current position |
| SGR | Set Graphics Rendition | CSI Pn m | Set format of screen and text (many available parameters, see dedicated sub-section) |
Set Graphics Rendition
The SGR function can be used with an arbitrary number of parameters from the table below, separated by semicolons.
Table (mostly) from Microsoft
| Value | Description | Behavior |
|---|---|---|
| 0 | Default | Returns all attributes to the default state prior to modification |
| 1 | Bold/Bright | Applies brightness/intensity flag to foreground color |
| 22 | No bold/bright | Removes brightness/intensity flag from foreground color |
| 4 | Underline | Adds underline |
| 24 | No underline | Removes underline |
| 7 | Negative | Swaps foreground and background colors |
| 27 | Positive (No negative) | Returns foreground/background to normal |
| 3 | Italics | Adds italic formatting |
| 30 | Foreground Black | Applies non-bold/bright black to foreground |
| 31 | Foreground Red | Applies non-bold/bright red to foreground |
| 32 | Foreground Green | Applies non-bold/bright green to foreground |
| 33 | Foreground Yellow | Applies non-bold/bright yellow to foreground |
| 34 | Foreground Blue | Applies non-bold/bright blue to foreground |
| 35 | Foreground Magenta | Applies non-bold/bright magenta to foreground |
| 36 | Foreground Cyan | Applies non-bold/bright cyan to foreground |
| 37 | Foreground White | Applies non-bold/bright white to foreground |
| 38 | Foreground Extended | Applies extended color value to the foreground (see details below) |
| 39 | Foreground Default | Applies only the foreground portion of the defaults (see 0) |
| 40 | Background Black | Applies non-bold/bright black to background |
| 41 | Background Red | Applies non-bold/bright red to background |
| 42 | Background Green | Applies non-bold/bright green to background |
| 43 | Background Yellow | Applies non-bold/bright yellow to background |
| 44 | Background Blue | Applies non-bold/bright blue to background |
| 45 | Background Magenta | Applies non-bold/bright magenta to background |
| 46 | Background Cyan | Applies non-bold/bright cyan to background |
| 47 | Background White | Applies non-bold/bright white to background |
| 48 | Background Extended | Applies extended color value to the background (see details below) |
| 49 | Background Default | Applies only the background portion of the defaults (see 0) |
| 90 | Bright Foreground Black | Applies bold/bright black to foreground |
| 91 | Bright Foreground Red | Applies bold/bright red to foreground |
| 92 | Bright Foreground Green | Applies bold/bright green to foreground |
| 93 | Bright Foreground Yellow | Applies bold/bright yellow to foreground |
| 94 | Bright Foreground Blue | Applies bold/bright blue to foreground |
| 95 | Bright Foreground Magenta | Applies bold/bright magenta to foreground |
| 96 | Bright Foreground Cyan | Applies bold/bright cyan to foreground |
| 97 | Bright Foreground White | Applies bold/bright white to foreground |
| 100 | Bright Background Black | Applies bold/bright black to background |
| 101 | Bright Background Red | Applies bold/bright red to background |
| 102 | Bright Background Green | Applies bold/bright green to background |
| 103 | Bright Background Yellow | Applies bold/bright yellow to background |
| 104 | Bright Background Blue | Applies bold/bright blue to background |
| 105 | Bright Background Magenta | Applies bold/bright magenta to background |
| 106 | Bright Background Cyan | Applies bold/bright cyan to background |
| 107 | Bright Background White | Applies bold/bright white to background |
Extended Color Subsequences:
| SGR Subsequence | Description |
|---|---|
| 38;2;r;g;b | Set foreground color to RGB value specified in r, g, b parameters* |
| 48;2;r;g;b | Set background color to RGB value specified in r, g, b parameters* |
| 38;5;s | Set foreground color to s index in 88 or 256 color table* |
| 48;5;s | Set background color to s index in 88 or 256 color table* |
*You can find an example of the referenced color table here
Selected DEC Control Functions
| Acronym | Name | Signature | Description |
|---|---|---|---|
| DECSC | Save Cursor | ESC 7 | Save cursor position in memory |
| DECSR | Restore Cursor | ESC 8 | Restore cursor position from memory |
| DECSET | DEC Private Mode Set | CSI ? Pn h | 25: show cursor; 1049: use alternate screen buffer; and many others |
| DECRST | DEC Private Mode Reset | CSI ? Pn l | Unset corresponding DECSET settings |
How to Use
To make use of control characters and functions in a modern terminal emulator, you need to know:
- How to input non-printable characters to your terminal
- The text encoding of your terminal
- How to represent the desired character(s) in said encoding
- Whether your terminal supports the targeted control character(s) and/or function(s)
1. Input Non-Printable Characters
Both Bash and PowerShell support various methods of inputting characters by their code points and/or byte representations.
Bash
printf will recognize the byte-representation of characters as octal in the format \ddd or hex in the format \xdd.
echo (when used with the -e flag) will recognize the same formats, plus common \ shorthands, like \e and \n. (printf recognizes \n but not \e.)
ESC=$(printf '\033')
echo "${ESC}[35mhello"
# OR for one-liners
printf '\033[35mhello'
echo -d '\x1b[35mhello
Important: Unlike PowerShell, both of these options will output exactly the bytes you input. If those bytes are not properly encoded according to your terminal's encoding, they will not work as expected. For example, if your terminal is using UTF-8 (quite likely), the raw, 8-bit CSI will not work if input as \x9b, because this is not the valid UTF-8 encoding. You must instead input it as \xc2\x9b.
Further Reading: Second answer on this Stack Overflow question
PowerShell
PowerShell does not recognize any of the formats supported by printf but does support multiple methods of inputting the byte-representation of characters.
A char instance can be declared by:
- casting the decimal value of any Unicode code point between
00andfftochar - casting the 2-byte hex representation of any Unicode code point in the "Basic Multilingual Plane" (BMP) to
char - calling the
ConvertFromUTF32function on the UTF32 hex representation of any Unicode code point
# Method One
Write-Host "$([char]27)[35mhello"
# Method Two
Write-Host "The trademark symbol is $([char]0x2122)"
# Method Three
Write-Host "A smiley face can be printed with $([char]::ConvertFromUTF32(0x1F60A))"
Bonus: The ESC character can be input with the keyboard combination CTRL+H.
Write-Host "^[[35mhello" # '^[' must be typed with CTRL+H
Important: PowerShell will write your characters to the terminal in whatever encoding the $OutputEncoding environment variable is set to. To change your output encoding, use [Console]::OutputEncoding = [System.Text.Encoding]::<encoding>. The default for PowerShell Core is UTF-8, and the default for PowerShell 5.1 and below is ascii.
2. Terminal Encoding
On Windows, the Console API can be used to query and set the input and output encodings of the console itself (distinct from the output encoding of PowerShell). In PowerShell, you can accomplish this with the following commands:
# Query
[System.Console]::InputEncoding
[System.Console]::OutputEncoding
# Set
[System.Console]::InputEncoding = [System.Text.Encoding]::<encoding>
[System.Console]::OutputEncoding = [System.Text.Encoding]::<encoding>
Unfortunately, there is no universal equivalent in the *nix world. There are relevant environment variables and the locale command, but these do not tell you the encoding of the actual terminal. The best method to determine a *nix terminal's encoding is trial and error. (The most common terminal encoding seems to be UTF-8.)
3. Character Representation
As briefly discussed in the "Input Non-Printable Characters" section, PowerShell will correctly encode the output of all characters according to the $OutputEncoding variable; Just make sure that this variable matches the input encoding of the terminal it is running within.
However, *nix tools for outputting non-printable characters will output exactly the bytes you enter in hex or octal representation. This means you need to know the encoding of the terminal you are working in and encode your characters accordingly.
If the terminal's encoding is UTF-8 (quite common), all characters with a code point between 00 and 7F can be input as a single byte. For larger code points, refer to UTF-8 documentation (or the Stack Overflow answer here).
4. Sequence Support
Most modern terminal emulators will support all or most of the standard ANSI escape sequences, documented in ECMA-48 (and Wikipedia).
Many terminal emulators support additional escape sequences. The two terminal emulators I've discussed in this article (xterm and the Windows Console) both support many of the DEC private use functions.
Microsoft documents their escape sequence support here.
xterm's escape sequence support is documented here.
Examples
Text Formatting
Format a title using both standard and private use sequences.
function Write-Title {
param(
[Parameter(mandatory=$true)]
[string]$Title
)
$ESC = [char]27
Write-Host ("$ESC#3" + "$ESC(0" + "$ESC[38;5;21m" + "l" + "q" * ($Title.Length + 2) + "k")
Write-Host ("$ESC#3" + "$ESC[38;5;21m" + "x " + "$ESC(B" + "$ESC[38;5;82m" + $Title + "$ESC[38;5;21m" + "$ESC(0 x")
Write-Host ("$ESC#4" + "$ESC[38;5;21m" + "x " + "$ESC(B" + "$ESC[38;5;82m" + $Title + "$ESC[38;5;21m" + "$ESC(0 x")
Write-Host ("$ESC#4" + "$ESC[38;5;21m" + "m" + "q" * ($Title.Length + 2) + "j")
Write-Host ("$ESC(B" + "$ESC[0m")
}
Note: this function makes use of two functions not discussed above, to include:
- DECDHL
- Switching character sets (specifically, to and from the DEC Line Drawing mode)
Screen Buffers
Switch to alternate screen buffer. Print text. Switch back to primary buffer on user input.
function Demo-ScreenBuffers {
$ESC = [char]27
$sequence = "$ESC[?1049h" + "$ESC[2J" + "$ESC[?25l"
Write-Host -NoNewline $sequence
Write-Host "You are now in the alternate screen buffer." + `
"Press ENTER to return to the main screen buffer"
Read-Host
$sequence = "$ESC[r" + "$ESC[?25h" + "$ESC[?1049l"
Write-Host -NoNewline $sequence
}
Cursor Control
Example 1
Insert text 5 lines above the current cursor position:
^[7^[[5A^[[L<YOUR TEXT HERE>^[8
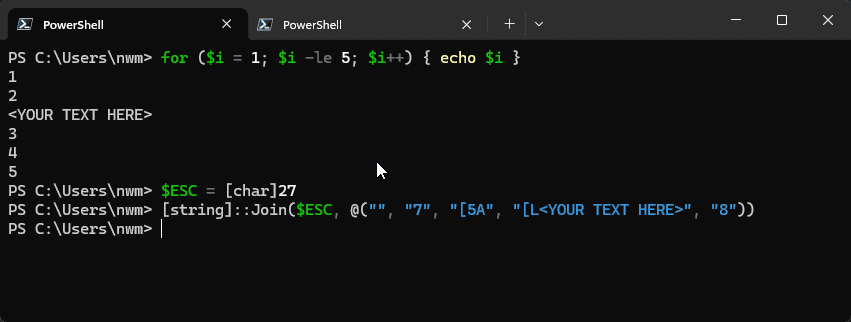
Example 2
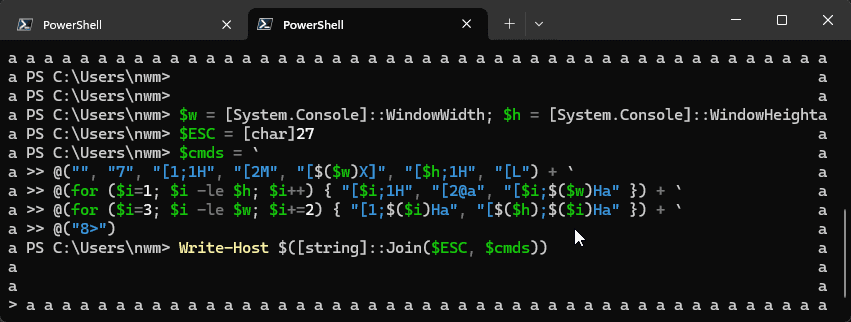
Print a border of 'a's around a PowerShell session, or around the CLI prompt
$w = [System.Console]::WindowWidth; $h = [System.Console]::WindowHeight
$ESC = [char]27
$cmds = `
@("", "7", "[1;1H", "[2M", "[$($w)X]", "[$h;1H", "[L") + `
@(for ($i=1; $i -le $h; $i++) { "[$i;1H", "[2@a", "[$i;$($w)Ha" }) + `
@(for ($i=3; $i -le $w; $i+=2) { "[1;$($i)Ha", "[$($h);$($i)Ha" }) + `
@("8>")
Write-Host $([string]::Join($ESC, $cmds))
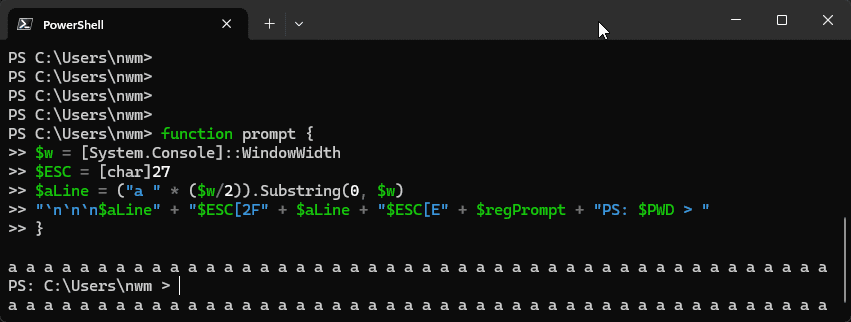
function prompt {
$w = [System.Console]::WindowWidth
$ESC = [char]27
$aLine = ("a " * ($w/2)).Substring(0, $w)
"`n`n`n$aLine" + "$ESC[2F" + $aLine + "$ESC[E" + $regPrompt + "PS: $PWD > "
}
Filename Trickery
In addition to expanded sets of printable characters, Unicode defines additional non-printable characters, including the "right-to-left" mark (RLM).
(See its Wikipedia page here.)
The RLM indicates that text should be displayed from right-to-left, as required by some languages. However, in the context of an English environmnet, this can be used for obfuscation or misdirection. The command below will create an executable scr file with an RLM in the filename, causing File Explorer to present it as a doc file.
New-Item -ItemType File -Path "$([char]0x202E)cod.tset.scr"
explorer.exe .
References
Standards
ASCII:
Escape Sequences:
- ECMA-48
- ANSI X3.64 (FIPS version)
- ISO 6429